研究发现:肿瘤蛋白标志物来自低丰度蛋白组
研究背景
血浆蛋白质组分析具有巨大的潜力,可以全面评估个体的健康状况。然而,由于血浆样本中蛋白质含量差异大,动态范围宽,以及个体之间和个体内部生物学差异大,因此血浆生物标志物的发现极具挑战性。
文章速递

研究思路
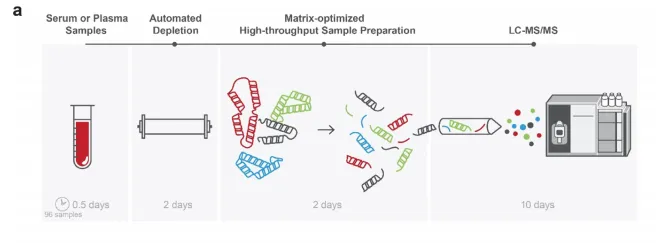
图1. 用于生物标志物发现的深度人体血浆分析流程
研究结果
深度解析血浆样本
该研究团队对来自美国胰腺癌、结直肠癌、乳腺癌、前列腺癌和非小细胞肺癌五种最致命实体癌症类型的不同人类180份血浆样本进行深度解析,共鉴定并量化了2732种蛋白质 (图2B)。深度解析可以覆盖血浆蛋白质组的8个数量级,包括组织渗漏蛋白、细胞因子和信号蛋白等 (图2C)。该研究团队进一步确定了 190 个 FDA 批准药物的靶点,其中 125 个(66%)属于较低强度范围。通过对注射、消化、去除和柱层析等步骤进行质量控制,可以评估引入的方差,并确保数据的可靠性 (图2D)。蛋白质鉴定数量随癌症类型而异,但都超过了1000种,表明该方法的深度和可靠性。
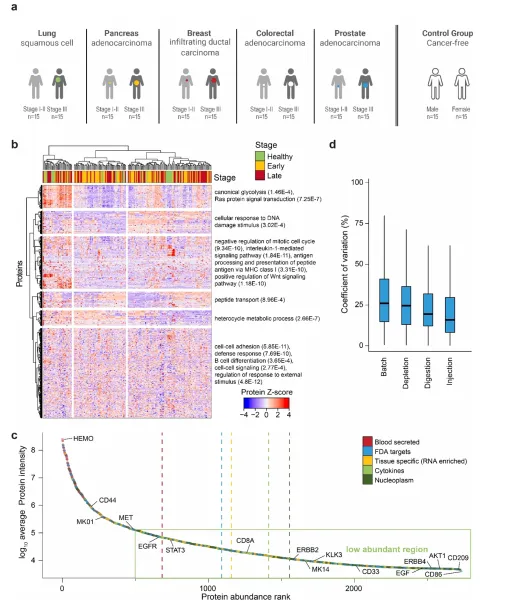
- 图2. 五种实体癌症类型的深度血浆发现蛋白质组学
不同癌症类型的异质性
该研究团队共纳入了 30 个对照样本,但每种癌症仅匹配 15 个子集。因此,对所有样本进行综合分析并不是本研究的主要目标。意识到这些局限性,该团队探索了整个数据集以寻找可以不可知地预测癌症分期的标记物。分析流程适用于整个数据集,癌症特定分析相同,旨在提供有关特定疾病发展的可行见解。
鉴于大量数据(合并 2732 种蛋白质),研究人员执行了两步法(图 3A)。首先,使用单变量分析筛选出健康、早期和晚期癌症之间的差异丰富蛋白质。在泛癌症模型中,发现 468 种蛋白质失调(图3B),其次,使用选定的蛋白质,基于 80% 的数据集训练了一个基于稀疏偏最小二乘判别分析 (sPLSDA) 的模型。此建模步骤进一步将蛋白质数量减少到 94 种(图 3B)。该模型部分区分了健康与疾病,但未区分晚期与早期。有趣的是,大多数分化蛋白质在纯血浆的检测水平以下,也就是大多数分化蛋白质都属于低丰度蛋白。(65%;图 3C)
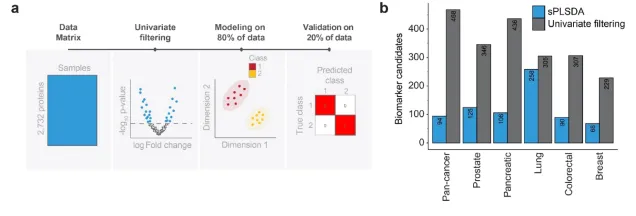
结直肠癌疾病状态分类
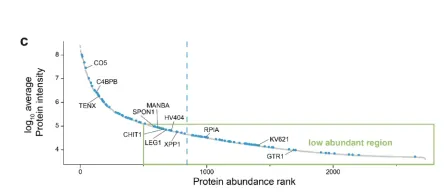
在结直肠癌 (CRC) 中,鉴定出 307 种在健康、早期和晚期阶段之间发生显著改变的蛋白质(图3A)。sPLSDA 模型进一步将这些候选蛋白质减少到 90 种,并且层次聚类和 PCA 分析均可有效区分健康受试者与患者(图3B)。
所选的 90 种蛋白质分布在测量蛋白质的整个强度范围内,其中 80% 以上的选定蛋白质(包括三种最重要的蛋白质,STAT3、TAGL 和 CD47)超出了 500 种蛋白质标记,属于低丰度蛋白。
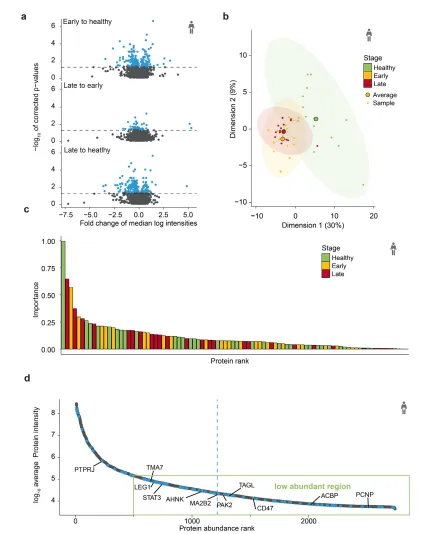
图3. 结直肠癌模型分析
胰腺癌的分期
在胰腺癌组中,436 种蛋白质在健康、早期和晚期阶段之间发生了显著改变(图 4A)。sPLSDA 建模选择了 106 种蛋白质,在层次聚类和 PCA 分析中均能有效区分这三个类别在早期胰腺癌中,参与调节肽分泌、细胞通讯和趋化因子产生的蛋白质总体下调,包括 LEG10,这对于 CD25 阳性调节性 T 细胞的抑制功能至关重要(图 4C),而参与负调节凋亡过程和受体内化的蛋白质(包括原癌基因酪氨酸蛋白激酶 Src (SRC) 上调。在晚期胰腺癌中,细胞氧化剂解毒和氧运输,包括血红蛋白亚基γ-1(HBG1)上调(图 4C)。最后在选定的125个生物标志物候选物中,65%处于低丰度范围(图4D)。在验证集中,该模型的准确率为66.7%。
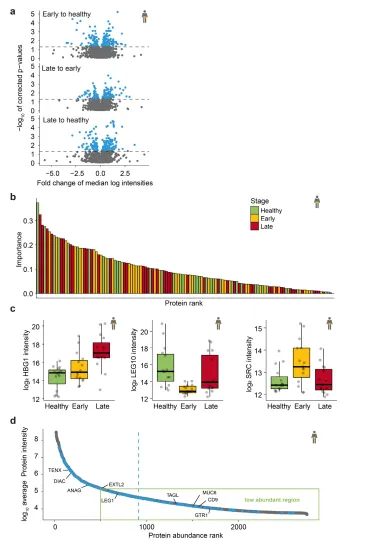
图4. 胰腺癌模型分析
总结
蛋白质组学深度解析的优势
深度覆盖: 通过深度解析血浆样本,可以更好地覆盖组织渗漏和信号分子区域,从而发现更多潜在的生物标志物 。深度解析可以覆盖低丰度蛋白区域,而浅层分析可能会错过这些蛋白质。
定量精度: 自动化去除流程和深度解析方法可以保持定量精度,从而提高生物标志物的可靠性。
生物标志物候选者: 大多数生物标志物候选者来自低丰度蛋白区域,这表明深度解析是必要的,因为浅层分析可能会错过这些蛋白质。
![]()